
Alexander Tsepkov Project Portfolio
Software developer and data geek with 18+ years delivering web, mobile, and defense systems that ship to production. My focus is on analytics platforms, APIs and developer tooling. My open-source work ranges from compilers and automation frameworks to GIS data products. I weave AI-assisted workflows into day-to-day engineering to accelerate delivery and quality.
The $2 AI That Rivals GPT-4
 Last month, DeepSeek R1 launched and Nvidia stock dropped 18% intraday. Silicon Valley panicked. A Chinese lab had trained a model with reasoning capabilities on par with GPT-4 for roughly $6 million, a fraction of what OpenAI spent. How they got there was disputed — OpenAI found evidence of DeepSeek-linked accounts scraping ChatGPT outputs for training data, while DeepSeek's paper showed a pure reinforcement learning approach on their own base model. But the method mattered less than the result: a $6 million model matching a $100 million one gutted the assumption that frontier AI required frontier budgets. Deepseek shattered the idea that API calls were reserved for corporations, now your hobby app can integrate with AI. Indeed, this seemed like an interesting integration for my Obsidian notebook. The plugin I started building already treated each task as a separate thread. But no one said that thread had to be executed by a human. What if I could research things directly from my notes as I type (no context switch)?
Last month, DeepSeek R1 launched and Nvidia stock dropped 18% intraday. Silicon Valley panicked. A Chinese lab had trained a model with reasoning capabilities on par with GPT-4 for roughly $6 million, a fraction of what OpenAI spent. How they got there was disputed — OpenAI found evidence of DeepSeek-linked accounts scraping ChatGPT outputs for training data, while DeepSeek's paper showed a pure reinforcement learning approach on their own base model. But the method mattered less than the result: a $6 million model matching a $100 million one gutted the assumption that frontier AI required frontier budgets. Deepseek shattered the idea that API calls were reserved for corporations, now your hobby app can integrate with AI. Indeed, this seemed like an interesting integration for my Obsidian notebook. The plugin I started building already treated each task as a separate thread. But no one said that thread had to be executed by a human. What if I could research things directly from my notes as I type (no context switch)?
I deposited $20 into DeepSeek's API account. After a month of heavy use, integrating it into my Obsidian-based workflow and running it against dozens of tasks I'd normally use ChatGPT for, my balance showed $18 remaining. Two dollars for a month of serious, daily use. Part of that month overlapped with DeepSeek's subsidized launch pricing, but even at full rates the gap with OpenAI is enormous.
Pennies Per Query
ChatGPT costs $20/month for the consumer subscription, which gives access to GPT-4 in the chat interface. But integrating AI into anything beyond chat means paying per-token on top of that subscription: API calls, automation, custom workflows, all billed separately. For anything beyond casual experimentation, that's hundreds per month. OpenAI and Anthropic built their pricing for organizations with engineering budgets. DeepSeek built pricing that an individual hobbyist can stomach. The per-token gap is not subtle:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| DeepSeek R1 | $0.55 | $2.19 |
| GPT-4 Turbo | $10.00 | $30.00 |
| GPT-4 | $30.00 | $60.00 |
GPT-4 costs 27x more per output token and 55x more on input. Even GPT-4 Turbo, OpenAI's cheaper variant, runs about 14x higher on output. Over a month of real usage, the same code generation, document analysis, and research synthesis tasks that would have cost $50-80 through OpenAI's API cost me $2 through DeepSeek. It was somewhat worse than Codex at writing code, but for most other tasks I would want to spawn from my notebook the reasoning quality is basically on par with GPT-4 – and noticeably better than other open-source models on Hugging Face today. Oh, and did I mention that DeepSeek also open-sourced this model?
This is a huge blow to OpenAI and an amazing opportunity for the solo inventor. By releasing R1, DeepSeek democratized corporate hold on AI. DeepSeek isn't identical to GPT-4, and there are edge cases where OpenAI pulls ahead on nuanced creative writing and complex multi-step reasoning. But for daily individual use, the results are close enough that a 14-55x price difference makes the choice obvious.
Cheaper Than Your Own Hardware
I'd been running local LLMs for months: Llama 2, Mistral, Phi, various open-source models on my Mac. No API costs, no data leaving my machine, full control. The reality didn't match the appeal.
The bottleneck is memory bandwidth. A 70B parameter model, the size class that competes with cloud quality, needs to read most of its weights from memory for every token it generates. My M2 Mac has 100 GB/s of memory bandwidth, which limits inference to about 2-3 tokens per second on a 70B model. In practice: 10-25 seconds to generate one sentence. I tried smaller models (7B, 13B) that ran at usable speeds, but the quality gap was immediately obvious. They hallucinate more, lose context in longer conversations, and often produce non-sensical output.
Getting usable speed (~20 tokens/sec) on a 70B model requires hardware that can move data fast enough: dual RTX 4090s with 48GB VRAM total, roughly $5,000 in GPUs alone, drawing about 1,000 watts under inference load. In Massachusetts, electricity runs about $0.30/kWh. That puts local inference at roughly $0.30/hour in electricity alone, before amortizing the $5,000 hardware investment. DeepSeek's API for equivalent throughput costs about $0.16/hour. The API is cheaper to run even if someone gave me the GPUs for free.
Data goes through Chinese servers. For proprietary code, client data, or sensitive business information, that's a non-starter. For personal projects, open-source work, and general-purpose AI tasks, the trade-off is straightforward.
Always-On AI for $2/Month
When API calls cost pennies instead of dollars, I no longer need to worry about costs, and prioritize user experience over my monthly bill. By intergrating DeepSeek API directly into my notebook, I've turned Obsidian into my own digital butler. And best of all, because the API follows the same standard as OpenAI (I love it when companies follow standards), corporate users with secrets they don't want leaking to China could easily swap the model for OpenAI or a local/private LLM.
At prices like this, I can in theory run AI against every note I take, every document I process, every piece of research I do, without watching a billing meter. Of course I also included safety guards:
- API calls are triggered by the user, AI can't randomly crawl your notes
- User chooses what context to send by explicitly linking it in, otherwise API only sees immediate children of the task
The best way to think about this design, is that user chooses where in their notebook to open a portal that can be used to interact with AI. AI can't escape this portal, but user can easily reference notes they want included via simple markdown:
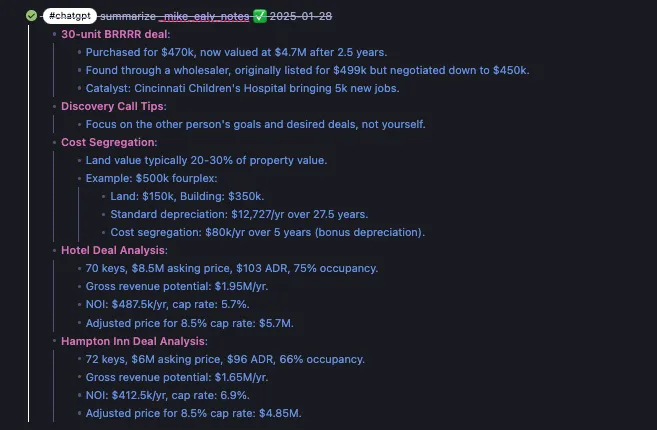 The system is simple, elegant, and safe. AI only touches the notes you want it to. The repo for this project is hosted on Github. The features discussed in this article are powered by the AI Connector.
The system is simple, elegant, and safe. AI only touches the notes you want it to. The repo for this project is hosted on Github. The features discussed in this article are powered by the AI Connector.
Related posts





