
Alexander Tsepkov Project Portfolio
Software developer and data geek with 18+ years delivering web, mobile, and defense systems that ship to production. My focus is on analytics platforms, APIs and developer tooling. My open-source work ranges from compilers and automation frameworks to GIS data products. I weave AI-assisted workflows into day-to-day engineering to accelerate delivery and quality.
Agentic Swarms: Are We There Yet?
 On any given day I have half a dozen Claude Code sessions running in separate tmux panes. A couple working on large architectural changes, a couple fixing bugs and polishing (one backend, one frontend), one fetching and curating fresh data sources, one doing research, one I bounce ideas off of like a rubber duck. Agents often go and do their own thing for 30+ minutes at a time, which means I can keep several in flight without babysitting. The coordination is all manual. I decide what each session works on, check if they're stepping on each other, merge the output. Organizing these agents into a team that works autonomously while I sleep felt like a natural next step. I found two projects in this niche, both vibe-coded.
On any given day I have half a dozen Claude Code sessions running in separate tmux panes. A couple working on large architectural changes, a couple fixing bugs and polishing (one backend, one frontend), one fetching and curating fresh data sources, one doing research, one I bounce ideas off of like a rubber duck. Agents often go and do their own thing for 30+ minutes at a time, which means I can keep several in flight without babysitting. The coordination is all manual. I decide what each session works on, check if they're stepping on each other, merge the output. Organizing these agents into a team that works autonomously while I sleep felt like a natural next step. I found two projects in this niche, both vibe-coded.
Gastown
 I wanted to like Gastown. It felt novel, and it came from the developer behind Beads, a project popular in the AI community for tracking tasks and issues between agents working together within a swarm. Think Jira for AI agents. If this person understood multi-agent coordination well enough to build the task tracker everyone was using, surely they could build a solid orchestration framework.
I wanted to like Gastown. It felt novel, and it came from the developer behind Beads, a project popular in the AI community for tracking tasks and issues between agents working together within a swarm. Think Jira for AI agents. If this person understood multi-agent coordination well enough to build the task tracker everyone was using, surely they could build a solid orchestration framework.
The first red flag was the origin story blog post. It ran 25+ pages. Not 25 pages of documentation or architecture diagrams. Twenty-five pages of rambling, unstructured stream of consciousness. I should have closed the tab right there, because in my experience, a person who can't tame their thoughts into an idea a five-year-old can understand is not going to build clean architectures. The inability to prune irrelevant clutter from your writing maps directly to the inability to prune it from your code. In software, pruning is the hard part. Anyone can write unmaintainable garbage that eventually arrives at the right answer. The real challenge is getting to the right answer with fewer moving parts.
And Gastown had a lot of moving parts. It ate through half of my weekly Claude Max Plan allowance in two days while sitting completely idle.
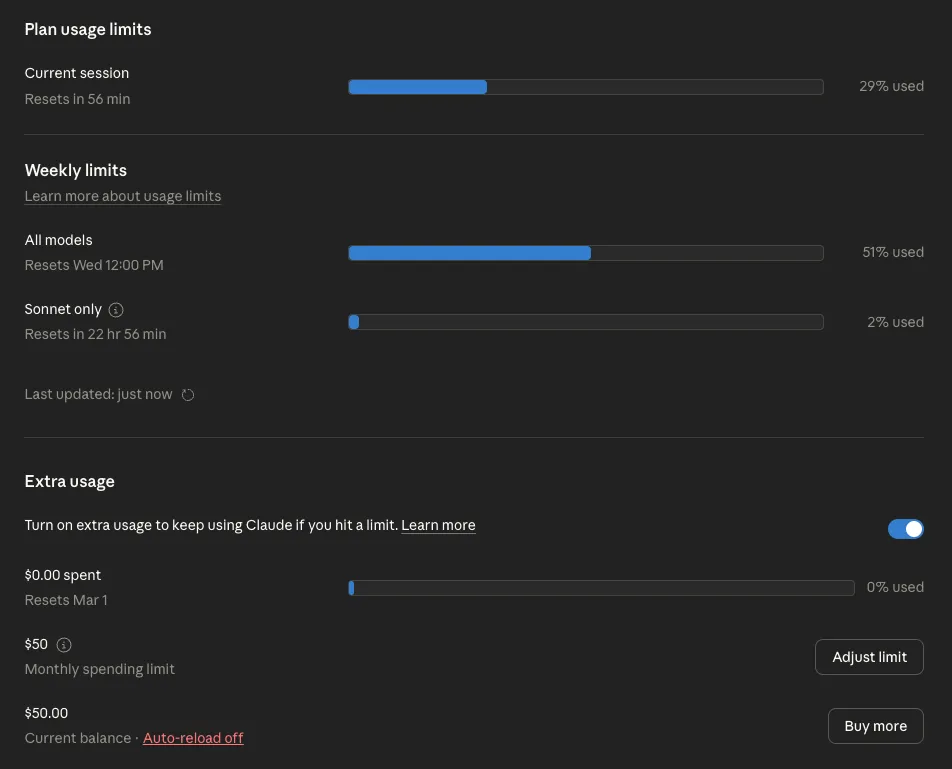 No jobs performed, no questions asked. Just a "mayor" and a few "deacons" running around the "town" doing nothing, burning through tokens asking each other if there was work to do, every few minutes, for 48 hours straight.
No jobs performed, no questions asked. Just a "mayor" and a few "deacons" running around the "town" doing nothing, burning through tokens asking each other if there was work to do, every few minutes, for 48 hours straight.
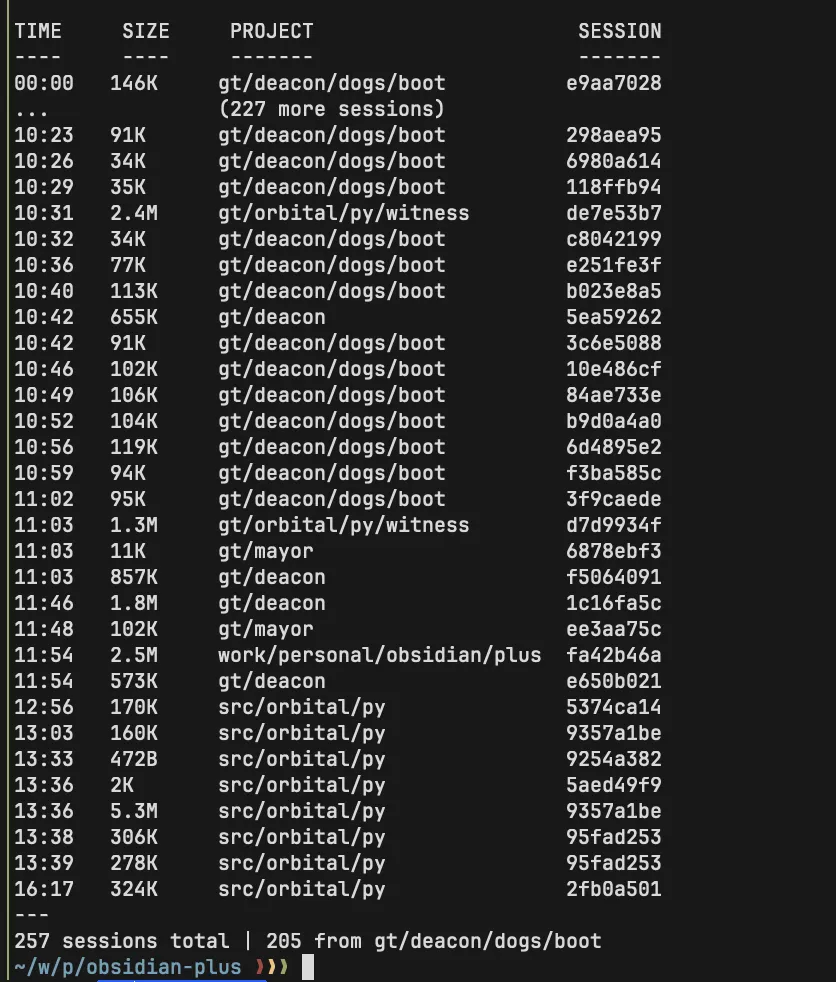 There is no reason to outsource a basic cron job to AI agents. If your system needs to check for new tasks periodically, that's a five-line shell script, not a conversation between two language models. This is an architectural red flag so fundamental that I'm surprised it shipped. In his opening blog post, the author bragged that he needed two max-plan Claude accounts to run the system and was thinking about getting a third. That's not a feature. That's a sign that the architecture is scaling the wrong thing. If my single, admittedly hyper-optimized Claude Code session does more autonomous work, faster, with a fraction of the tokens, the problem isn't that he needs more accounts. The problem is garbage in, garbage out.
There is no reason to outsource a basic cron job to AI agents. If your system needs to check for new tasks periodically, that's a five-line shell script, not a conversation between two language models. This is an architectural red flag so fundamental that I'm surprised it shipped. In his opening blog post, the author bragged that he needed two max-plan Claude accounts to run the system and was thinking about getting a third. That's not a feature. That's a sign that the architecture is scaling the wrong thing. If my single, admittedly hyper-optimized Claude Code session does more autonomous work, faster, with a fraction of the tokens, the problem isn't that he needs more accounts. The problem is garbage in, garbage out.
270,000 Lines of Go for a To-Do List
This apathy toward efficiency made me wonder what else was wrong under the hood. I started scrutinizing Beads too, the project that gave this developer credibility in the first place. I found the same pattern: irrelevant abstractions layered on top of each other. "Wisps." "Molecules." Concepts that sound clever but add complexity without solving a real problem. The repository clocked in at roughly 270k lines of Go for a task management system. I rebuilt the same functionality in about 700 lines of Node.js and a SQLite file. I called it op-tasks.
The difference isn't about language choice or cleverness. It's about understanding what the problem actually requires and refusing to build anything beyond that. Idle agents burning tokens, a 25-page blog post that never finds its point, 270,000 lines of Go for a to-do list — the pattern keeps repeating. And Beads wasn't just a Gastown problem. The other framework I was evaluating, Overstory, depended on it too.
Overstory
The second framework I evaluated was Overstory. Also vibe-coded, but meaningfully cleaner. Where Gastown felt like a Rube Goldberg machine, Overstory had a coherent mental model of how agents should coordinate. It wasn't perfect, but the bones were good enough to build on.
I picked Overstory as the base for my orchestrator and started fixing what needed fixing. The tmux integration was the first headache. Overstory assumed it owned my terminal: it wanted to spin up its own tmux sessions and drive everything from scratch. I use tmux heavily in my daily workflow, and Overstory was not designed to work within an existing session. It wanted to be the driver, not a passenger. It took about 1,200 lines of code just to make it respect an existing tmux session, and in hindsight, running two separate tmux servers might have been simpler. I also ripped out the Beads dependency and replaced it with a leaner ticket-tracking system . What Beads did with 200k+ lines of code, I was able to do in 700.
The result was better than Gastown, which was basically just a token bonfire. But after playing with it more, I came to a sobering realization: the agents still weren't ready for unsupervised work. I'm not alone in this assessment. Overstory's own steelman document is refreshingly honest about the failure modes: a 20-agent swarm consumed 8 million tokens ($60) over 6 hours to do what a single agent accomplished for $9 in 8 hours. The speedup cost $51 in coordination overhead. Compounding errors, architectural drift, and "forensic reconstruction" debugging are described as "the normal case, not edge cases." Even Addy Osmani, who wrote extensively about Claude Code agent teams, called them experimental and warned that activity doesn't always translate to value — agents churning out large volumes of code at impressive speed, none of which guarantees the code is actually correct.
The Patterns That Work
The idea of composing agents into teams isn't wrong. For example, adversarial agents (where one agent's goal is to complete a task, and the other agent's goal is to break the first agent's code) are great at converging on a working solution. Google recently published research on multi-agent design patterns that lays out 8 patterns, ranging from simple to complex. The framework mirrors microservices architecture: specialize for reliability and debuggability. There are legitimate merits to agents working in teams: better focus, less context pollution.
The simpler patterns work today. Sequential Pipeline (each agent's output feeds the next) is reliable for deterministic data processing. Parallel Fan-Out (multiple agents run simultaneously, a synthesizer aggregates) delivers real value for tasks that benefit from diverse perspectives, like code review where separate agents check security, style, and performance in parallel. Generator/Critic (one agent generates, another validates against hard criteria) is great for binary correctness checks: does this SQL query return the right results, does this config pass validation.
The patterns that sound most impressive on paper are the ones that fall apart in practice. Hierarchical Decomposition (a high-level agent breaks goals into sub-tasks and delegates down) suffers from premature decomposition: breaking problems into subtasks before fully understanding them causes overlapping concerns, missed dependencies, and wrong abstraction choices. This is exactly the failure mode Overstory documents. Iterative Refinement (generate, critique, refine in a loop until quality threshold) has no guaranteed convergence, agents can spin endlessly refining without getting closer to the goal.
So which patterns actually hold up? Human-in-the-Loop is the only pattern that works for anything with real stakes right now. Claude Code already spawns sub-agents under the hood as needed in patterns similar to ones documented by the Google research paper. Watch it tackle something complex and you'll see it spawning sub-agents to search the codebase, run tests, and validate changes, while routing the important decisions back to you.
 If a multi-agent pattern genuinely works, Anthropic will fold it into native Claude Code within weeks — they have a surprisingly good intuition for what developers actually want. Rather than building a custom orchestration layer that'll be obsolete by next month, the sweet spot is ironically just using vanilla Claude Code (or Codex, depending on the bandwagon you happen to be on).
If a multi-agent pattern genuinely works, Anthropic will fold it into native Claude Code within weeks — they have a surprisingly good intuition for what developers actually want. Rather than building a custom orchestration layer that'll be obsolete by next month, the sweet spot is ironically just using vanilla Claude Code (or Codex, depending on the bandwagon you happen to be on).
The Elephant in the Room
AI is not ready for autonomous work on anything complex. I've seen the failure modes firsthand, and they're not subtle edge cases. They're fundamental gaps in how AI approaches problems. I had an agent build a SQL query that drove from the wrong index. The query (selecting 250k local businesses from Investomation database) worked, returned correct results, and took 18 seconds to execute. Asking Claude to improve the performance resulted in it trying to optimize my frontend rendering – it claimed the slowdown was due to rendering reflows. The optimizations it suggested (replacing SVG nodes with canvas) made sense on paper, but completely missed the real culprit. On the frontend, the businesses rendered as clusters, grouping 250k businesses into just 500 objects – a 10-year old laptop can handle that.
It took a human to point out that the real issue was the SQL query itself. Something that was obvious to me was not obvious to Claude. Even after focusing on the SQL itself, Claude was driving from the most generic county-based index. It then recommended compound index, bolting on additional columns that added complexity without noticeable improvement. But as soon as I pointed out that it should be driving from the most specific coordinate-based index (which would have been obvious to anyone with SQL-tuning experience), the query time changed from 18s to 0.4s.
In another project, an agent defaulted to using the client as the source of truth for a chat system. If you're not a developer, that sounds fine. If you are, you know that's a recipe for data loss, race conditions, and security holes. The server is the source of truth, always. This isn't a nuanced architectural debate. It's a basic principle that any mid-level engineer knows, and AI cheerfully violated it because the client-first approach was simpler to implement.
These aren't cherry-picked horror stories. This is what happens on a regular Tuesday when AI works without supervision. The failure mode isn't that AI produces garbage, it's that AI produces plausible-looking output that passes a casual glance but crumbles under expert scrutiny. AI lacks the architectural intuition, the performance tuning instinct, the "this smells wrong" reflex that comes from years of seeing systems fail in production. Without a human in the loop who has that intuition, the output is a coin flip between acceptable and quietly catastrophic. The potential of agentic swarms is real. I dream of a future when AI can write code while I sleep (pun intended). But we're simply not there yet.
Related posts





